

前回は生成AIの産業構造を分析し、生成AI市場がバブルかどうかを分析しました。
分析した結果、生成AI市場はバブルの状態で、過去の大きなバブルと比較すると典型的なバブル中期を越えていると結論付けました。しかしながらバブルは残念ながら、歴史的にノーダメージで切り抜けられた事実は過去に存在しません。
そこで今回は、生成AIバブルが崩壊するならどんなシナリオ、時期を産業構造から考えて行きましょう。
まずは一般的なバブル崩壊のメカニズムを歴史上のバブルから解析します。
バブルの崩壊メカニズム
そもそもバブルとは以下のように定義されています。
不動産や株式をはじめとした時価資産価格が、投機によって経済成長以上のペースで高騰して実体経済から大幅にかけ離れること
もっと簡単に言うと、不動産や株式などが将来的にもっと高くなるだろうという期待が膨らんで、その時の実体的な価値(価格など)より大幅な高い価値(価格など)で取引される状態です。
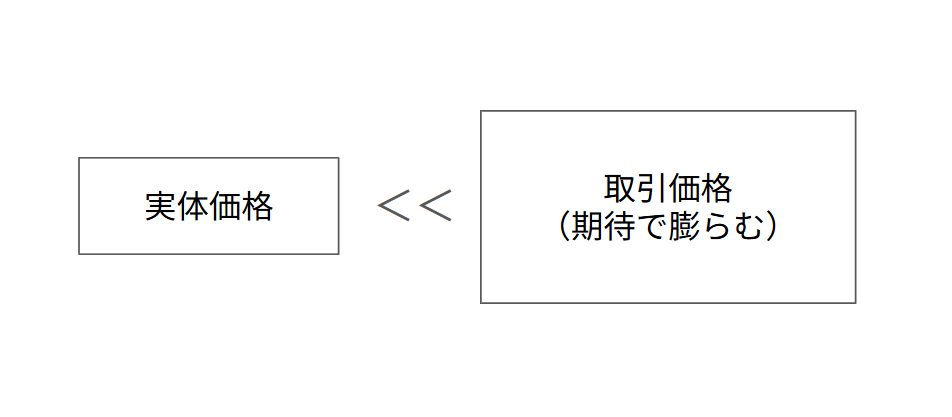
つまりバブルが膨らむ源は将来への期待と考えて間違いありません。
このことからバブル崩壊のメカニズムを考えると、その将来への期待が崩れた時に崩壊が始まるわけです。つまり”将来的に上がるだろうと期待した価格に対し、どうやら辿りつかなさそうだ”となった時がトリガーになります。
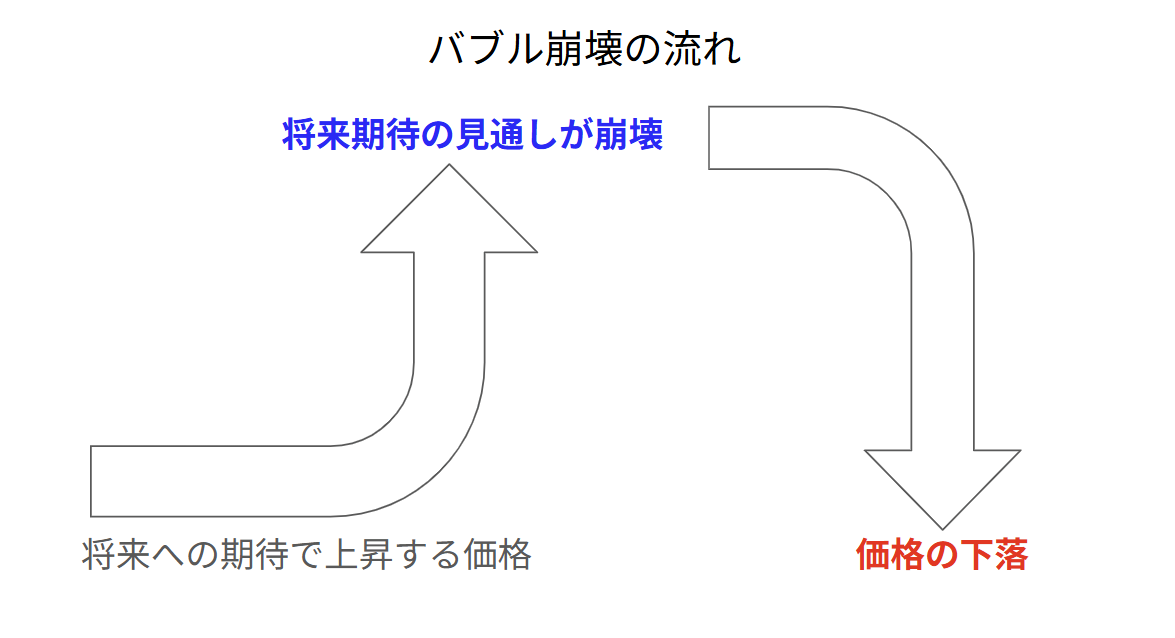
これを簡単な不等号で表すと下記のようになります。
この不等式が成り立つと一気にバブルが崩壊します。
実際に歴史的なバブル崩壊のメカニズムを見ると下記のようになります。
- チューリップバブル(1630年代、オランダ)
珍しい品種のチューリップ球根が希少価値から投機対象になり、球根一個が熟練職人の年収の数十倍まで高騰。”希少なものは値上がりし続ける”という期待が崩れた瞬間に買い手が消滅し暴落。史上初の投機バブル - 鉄道バブル(1840年代・イギリス)
“蒸気機関車による鉄道網の拡大”への期待で鉄道会社への投資が爆発的に増加。実際に敷設できる路線数をはるかに超える計画が乱立し、過剰投資が明らかになった段階で崩壊。インフラ建設への先行投資がバブルを膨らませたことが特徴。 - 日本の土地バブル(1980年代後半)
”土地は必ず値上がりする”という土地神話を背景に不動産・株への投機が過熱。日銀の急激な利上げがトリガーとなり地価が暴落、金融機関の不良債権が顕在化して崩壊。失われた30年の起点となった。 - ITバブル(1990年代後半・ドットコムバブル)
インターネットの普及により”ネット企業は無限に成長する”という期待で赤字企業にも巨額投資が集中。実際の収益化が見込めないことが明らかになり2000年に崩壊。
いずれのパターンも、将来への期待によってバブルが膨らみ、実体がその期待に伴っていないと判明した時点でバブルが崩壊しています。
直近で発生したバブル崩壊は、覚えている方も多いであろうサブプライムローン住宅ローンを起因としたリーマンショックになります。

簡単に解説するとサブプライムローンバブルの源の期待は”アメリカでは必ず人口が増加するので住宅は増加、必ず住宅価格は上がる”ことでした。
その期待を源にローン返済能力が低い人(サブプライム層)へ、住宅代をローンで無理に貸し出します(サブプライムローン)。その貸出担保は”将来、必ず住宅価格が上昇する”でした(悪質な残価クレジットみたいなもの)。さらにタチが悪いのがサブプライムローンは、変動金利性でした(政策金利連動型のローン)。
そのサププライムローンの債権が、手堅い金融商品として世界中に販売されました。
しかしながらバブルの源の期待は住宅の過剰供給によって住宅価格の上昇が滞ります。追い打ちを掛けてFRB(連邦準備制度理事会)が政策金利を段階的に1~5.2%まで引き上げました。
これによって住宅ローン(サブプライムローン)で破綻する人が一部で出てきます。そのローンの不履行で差し押さえた中古物件が市場に出てきて、さらに住宅価格が下がります。サブプライムローンは、そもそも住宅価格の上昇が担保なので住宅価格の下落により、大量のローン不履行が出てきます。

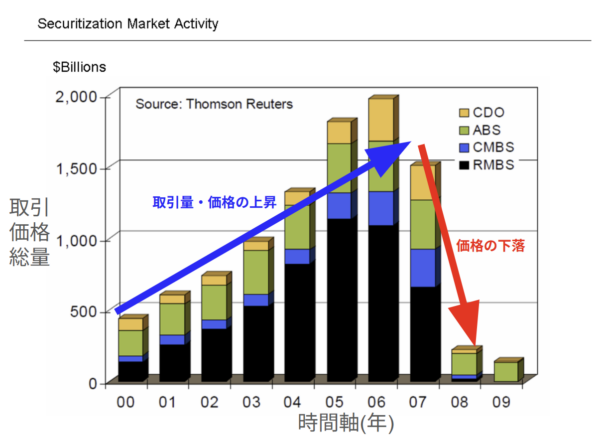
ここでサブプライムローンの債権が紙クズとなりバブルが崩壊したわけです。
このように直近のバブルでも過去の歴史と全く同じように期待(アメリカでの住宅増加・価格上昇)は破綻することによってバブルが崩壊しました。
では、次に生成AI市場バブルの源になる期待は何か?を考えて行きましょう。
生成AIバブルの源(期待)は何か?
まず前回の振り返りにもなりますが、代表的な生成AI会社であるOpen AI(chatgpt)、Anthropic(claude)の共に2025年は大きな赤字です。
※執筆時点の2026年2月においては各生成AIは設立以来、一度も黒字化していない。現状だと生成AIの産業構造上、必ず赤字になる。
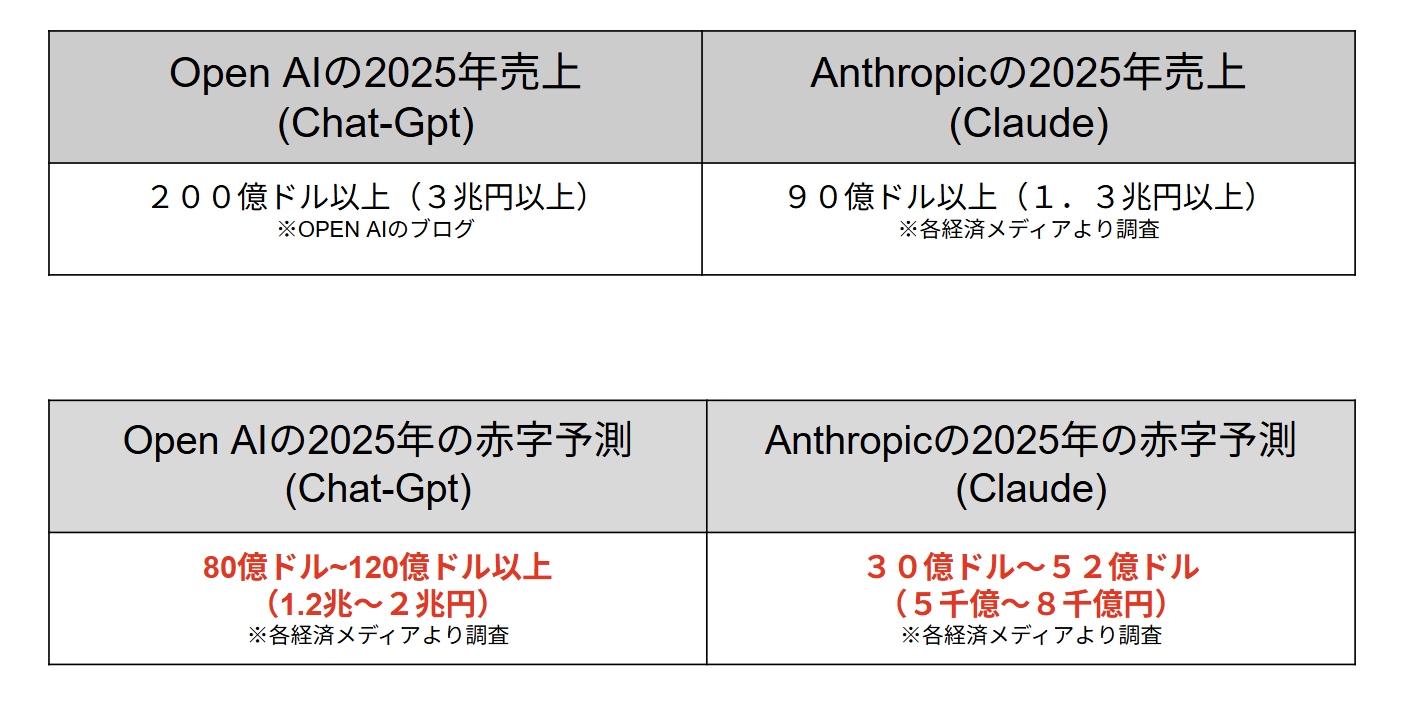
つまり2025年の実体収益である生成AIサブスク・API代では黒字は程遠い数字になっています(実体との乖離)。むしろOpen AI、Anthropicも普及帯プランの月のサブスク代20ドルの背後には、12ドルの赤字が隠れています。
※最近できた入門プランはもっとか赤字の可能性が高い、逆に言えばお得
赤字にも関わらず、さらなる大規模投資も行われています。

これらの資金は”生成AIへが将来に莫大な利益を生み出すだろう”という期待を源に資金が注入されている状況です。
ただし前回で説明した通り現在の生成AIの産業構造、収益方法(サブスク・API代金)で黒字にするのはかなり難易度が高い状況です。
※黒字化は産業構造上、現状ではほぼ不可能。現状の構造で黒字化を可能にする唯一の方法が推論モデルの計算リソースの革命的な削減が必要
そうなると投資家達の期待は、莫大な利益を生む何かしらの変化(パラダイムシフト)になります。その変化を各生成AI会社のCEOの発言から読み解いていきます。

- 我々はAGIの構築方法を確信を持って理解している(2025年1月トランプ大統領への発言)
※AGIとは汎用人工知能のこと、つまり誰でも何にでも使える人工知能のこと - AIは人類史上最大の経済成長をもたらす(2025年1月トランプ大統領への発言)

- 強力なAIが開発されれば、生物学・医学において21世紀全体で達成できたはずの進歩を数年で実現できる(2024年10月 自身のエッセイ)
- 2〜3年で職場に登場し、ほぼあらゆることで人間を超えるモデルが実現すると確信している(2025年1月・ダボス会議)
これらの発言により現状のサブスク・API代の延長ではなく、社会基盤化(インフラ)しようと考えていることがよくわかります。
これを裏付けるかのように投資家達も次のように発言しています。
- AGIは2〜3年で実現し、人類の叡智の1万倍のASI(人工超知能)が10年以内に来る(SoftBank world 2024 孫正義氏の発言)
- AIを使わないのは電気を使わないのと同じ(孫正義氏)
- 今後100年、200年、300年先の人類の未来に影響を与える(孫正義氏)
- 全容はまだ分からないが、その影響が並外れたものになることは確信している。AIは蒸気機関、電気、そしてインターネットに匹敵する(JP モルガン CEO)
- 2026年、最大のインフラ衝撃は外部からではなく、内部からやってくる。人間速度のトラフィックから、再帰的で爆発的かつ巨大な「エージェント速度」のワークロードへと移行するのだ。(a16z CEO)
これらの発言から共通項を考えると、生成AIが電気・ガス・水道や電車・道路などのような社会インフラになることが、バブルの期待の源であると考えて間違いないでしょう。
つまり生成AIバブルの源でる期待の正体は、”社会インフラ化”であると断定してほぼ間違いないでしょう。
その社会インフラ化とは、具体的に何を示すのかは各生成AI会社のCEO、投資家からの発言ではわかりませんが、インフラとして使われるためには最低でも以下の条件が必須です。
- 信頼性(常時稼働、誤作動しないなど)
- コスト(誰にでも払える水準)
- 普遍性(専門知識なく使える、生活に組み込まれる)
- スケーラビリティ(利用者が増加しても問題が発生しない)
そうすると本記事の主題である生成AIバブルの崩壊シナリオの起点は、社会インフラ化が達成できない、もしくは社会インフラ化が期待値に沿う速度で達成できなかった時に発生するのが歴史の事実から判明します。
そこで次に”生成AIの社会インフラ化”への課題を考えることによって、バブル崩壊の起点を探っていきます。
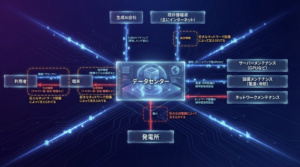
社会インフラ化への達成への課題を、前回の図を基にGPUなどのAI演算チップ、電力などのハード的な側面と生成AIソフト、学習データなどのソフト面の2つの観点から考えて行きます。
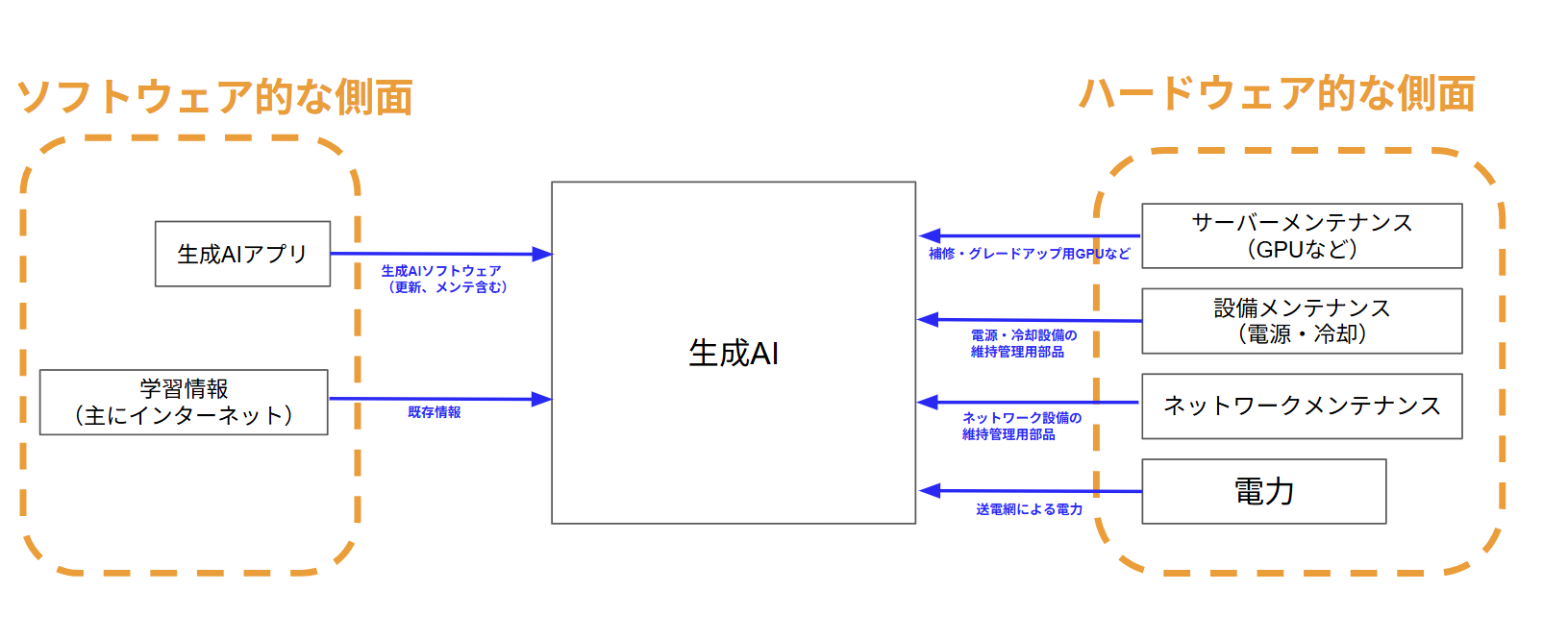
ハード面(AI演算チップ、電力など)の課題
ハード面において生成AIの社会インフラ化で大きく影響を及ぼすのは信頼性、コスト、スケーラビリティの3つになります。簡単に言い換えると常に確実に動く、生成AIの利用料が誰にでも払える、莫大な数の利用者が使っても破綻しないデータセンターが必須になるということです。

このことからデータセンターに求められる要件は最低でも以下の能力が必須になります。
- 常に確実に動く・・・電力の安定供給が必須
- 誰にでも払える・・・AIの演算コストの低下が必須(AI演算チップに多く依存)
- 莫大な利用者へ対応する・・・演算能力の拡張(AI演算チップに大きく依存)・データセンター数の増加
これらのことからデータセンターに関してボトルネックになる大きな要素はAI演算チップの安定供給、電力の安定供給の2つがカギになることがわかると思います。
※データセンターの数自体は新規建設計画が多数あるので、ボトルネックにはならないと思う。
次に各課題を少し詳しく見て行きます。
AI演算チップ(GPUなど)の安定供給の課題
まずAI演算チップの需要のボリューム感を掴んでいきましょう。
おおよそ生成AIで使われるデータセンターには、演算ラックが標準的な規模で1000台、大規模なデータセンターだと5000台ほど設置されています。その演算ラック1台にAI演算チップは8枚ほど使うのが標準セットになります。


よってデーセンター1カ所あたり、AI演算チップがおおよそ8000~40,000枚と大量に必要になります。
このデータセンターが2025年の3月時点、アメリカ国内限定でも5426カ所も存在しています。そう考えると規模感だけでも数千万枚~数億枚レベルになります。これを世界規模に広げると具体的な数字はわかりませんが必要なAI演算チップ数は十数億枚レベルでもおかしくありません。
ここまでは既存設備の数から導き出したAI演算チップの総数を出しただけなので毎年、十数億枚の需要があるわけではありませんが、新設のデータセンター用、故障などによるトラブルでの交換(意外とそこそこ壊れる)、チップの進化の速さに伴う世代間の性能格差による置き換えによって毎年、膨大な需要が発生しています。
実際に2025年のAIサーバー用の演算ユニットの出荷総量が1000~1200万ユニット、そのユニットに4~8個のAI演算チップが搭載されています。


この膨大なAI演算チップの需要を賄っているのが、業界シェア80~90%と言われているNVIDIAになります。そのNVIDIAのAI演算チップ(AI演算用のGPU)の生産のほとんどを請け負ってるのが台湾のTSMCの一社だけという状態です。


当然ながら年間で1000万ユニットを越えるレベルの需要を完全に満たしている状況ではなく、2025~2026年にかけては完全に供給不足に陥ってます。
このことからAI演算用のGPUは経済構造的に価格の低下が進みにくいので、社会インフラ化のための要件のAIの演算コスト低下、演算能力の拡張の大きな課題になっています。
電力安定供給の課題
電力もAI演算チップ同様に、まずは電力需要の全体像から掴んで行きましょう。上記のAI演算チップで出てきた世界需要の十数億枚を動かすだけでもとんでもない電力が必要そうなのは感覚的にわかると思います。
2022~2023年に登場し業界の標準的なGPUであるNVIDIA H100を例にすると一枚あたりの消費電力が約700Wなので、十数億枚を概算すると70GWになります。
※より新しいのはもっと電力を消費する、、話題の最新チップのBlackwell(B200)は1000~1200W。

この70GWは日本の総発電容量が300GWなのでおおよそ25%にあたります。
もちろんのことデータセンターはAI演算以外にも冷却、通信などで電力を消費するので必要電力は70GW以上になります。
国際エネルギー機関(IEA)によると、データセンターの電力消費は2026年までに1,000TWh(テラワットアワー)を超えるとされており、これはEUをけん引する産業大国ドイツ一国の年間総電力消費に匹敵する規模になります。しかもこの数字はAI普及前の水準からわずか数年で倍増する計算になります。
このことから生成AIを運営する各社は安定した電力確保に必死になっています。
- Microsoft:スリーマイル島原発を再稼働、20年契約・835MW全量購入
※有名な事故のスリーマイル原発 - Amazon:Susquehanna原発と10年契約、SMR開発にも投資
※SMRとは話題の次世代小型原子炉のこと - Google:Kairos PowerとSMR開発契約、2030年までに500MW
- Oracle:送電網接続を待てず、ガス発電機による自前発電を検討、年間運営コスト1,000億円超の予定
この各社の必死の努力で現在の生成AIがなんとか稼働出来ている状態です。
このような電力供給事情にも関わらず、新しい巨大なデータセンター建設計画であるスターゲート計画、Anthropic独自の巨大データセンター、Microsoft、Google、Amazonなどのクラウド拡張計画がどんどん推進されています。
結局のところ電力も需要が供給に大幅に上回っている状態なので、AI演算チップ同様に経済構造上、電力価格の低下、安定供給が進みにくいので、社会インフラ化のための要件の常に確実に動く、AIの演算コスト低下、莫大な利用者への対応への大きな課題となっています。
ハードの課題がバブル崩壊の起点になり得るか?
ここまでの解説からハード面の社会インフラ化への代表的な課題であるAI演算チップ・電力の安定供給問題がバブル崩壊の起点になるかと言うと、私の考えでは起点にならないと思います。
理由をいくつか述べて行きましょう。
AI演算チップの安定供給問題に対しては生成AI各社で既に対応の動きが開始されており、改善の兆しが見え始めています。
- Googleは独自の自社製チップを使用
- Amazonは独自の自社製チップを使用(NVIDIAのGPUと共存)
- Open AIはBroadcomと自社専用チップの開発を開始
- AnthropicはBroadcomと自社専用チップの開発を開始
- Cerebras (セレブラス)などの新たなプレイヤーも出てきている
各社の対応により現在のNVIDIA一社に頼り切っていると言って良い供給体制が打開される可能性が出てきています。
またNVIDIAも現状を良しとせずにTSMCに変わる新たな生産拠点の確保(intel系の企業の活用検討)やTSMC自体も増産・拠点増加計画を発表しています。
AI演算チップ自体も、様々な課題はあるものの、現代より圧倒的に高性能な次世代チップの開発を強力に進めています。
電力供給問題も同様に対応に時間は掛かるものの休止した原発の再稼働、新規のガス発電所で乗り切ろうとしています。最悪時はコスト高に繋がるモノの自家ガス発電で乗り切る手もあります。
※Oracleが検討中
またSMR(次世代小型原子力発電ユニット)の開発も様々な課題があるものの着実に進んでいます。
※SMRの基盤技術は原潜とか原子力空母なので純技術的蓄積はある、民間でのコスト、安全性や法律などが課題になる。


いずれの課題もAIの社会インフラ化を不可能にする要素ではなく、タイミングを遅らせるレベルに留まります。第一章で述べたようにバブルにとっては社会インフラ化が実現する速度・タイミングも重要ですが、論理的かつ物理利的に解決可能策が明確である場合は、バブルの源である”社会インフラ化”への期待を裏切る要素にはなりにくいと考えます。
逆にAIの社会インフラ化へのステップを加速させるためにバブルがさらに膨らむ可能性があります。この問題はお金の投下である程度、問題のコントロールが可能なため資金を集める口実にすることもできます。つまりバブル崩壊起点ではなく競争激化の要因になると考えます。
※AI演算チップ、電力の安定確保によって業界内で勝ち負けは出るかも知れない。
ソフト面(生成AIソフトウェア、学習データ)の課題
ここではソフト面がAIの社会インフラ化に影響を及ぼす課題を考えて行きましょう。ハード面と同様に、社会インフラ化の4つの要件との関係を整理すると、ソフト面はハード面以上に広範囲に影響を及ぼします。
- 信頼性(誤作動しないこと)・・・明らかな間違いの極小化(ハルシネーション低減など)
- コスト(誰にでも払える水準)・・・推論コストの大幅な低減(推論コストの軽量化など)
- 普遍性(専門知識なく使える、生活に組み込まれる)・・・使い勝手の大幅向上(UIの向上、適用可能範囲の拡大、高度なローカライズなど)
- スケーラビリティ(利用者が増加しても問題が発生しない)・・・推論コストの大幅な低減(推論コストの軽量化など)
上記の課題をさらに具体化させると次のように言い換えられます。
- ハルシネーションの低減・・・推論モデルの改良、高品質で大量の学習データ
- 推論コストの軽量化・・・推論モデルの改良
- UIの向上・・・生成AIアプリの改良
- 適用可能範囲の拡大(マルチモーダル化)・・・生成AIアプリの改良(画像など)、多様な領域の高品質な学習データ
- 高度なローカライズ(現地化)・・・生成AIアプリの改良(多言語化など)、多国籍に渡る高品質で大量の学習データ
上の図からわかるように社会インフラ化のカギとなるソフト面の課題は推論モデルの改良・高品質で大量の学習データの2項目に絞れます。
※生成AIアプリの改良は純技術的な難易度はさほど高くないと思うので省略
つまり生成AIが社会インフラ化するための必須条件は推論モデルの大幅な軽量化・高品質な学習データを枯渇させないことになります。
次にこの2項目について深堀りをして行きますが、私は機械設計(エンジン設計)出身でAIのプログラミング、アルゴリズムの深い知識は持っていないので学習データの枯渇問題に絞って考えて行きます。
学習データ枯渇問題
この問題を考えるに当たって最初に学習データが完全に枯渇した場合に何が起きるかを考えてみましょう。前提として現在の生成AIは確率論的に動作する仕組み上、ハルシネーション(誤情報の生成)をゼロにすることは構造上不可能です。
※現在の生成AIのアルゴリズムは確率論に基いてるからハルシネーション率0%は絶対に不可能。
学習データが完全に枯渇した世界を想像して下さい。その世界の中でユーザーからの質問に生成AIが答えます。その解答には必ず一定の割合でハルシネーションが含まれます。そのハルシネーションがネット上に蓄積され、そのハルシネーションを含んだ情報を学習し、新たなユーザーの解答にその情報が利用されるわけです。つまり使えば使うほどハルシネーションからの引用が増えて行くわけです。
※話題のエコーチャンバーと全く同じメカニズム。
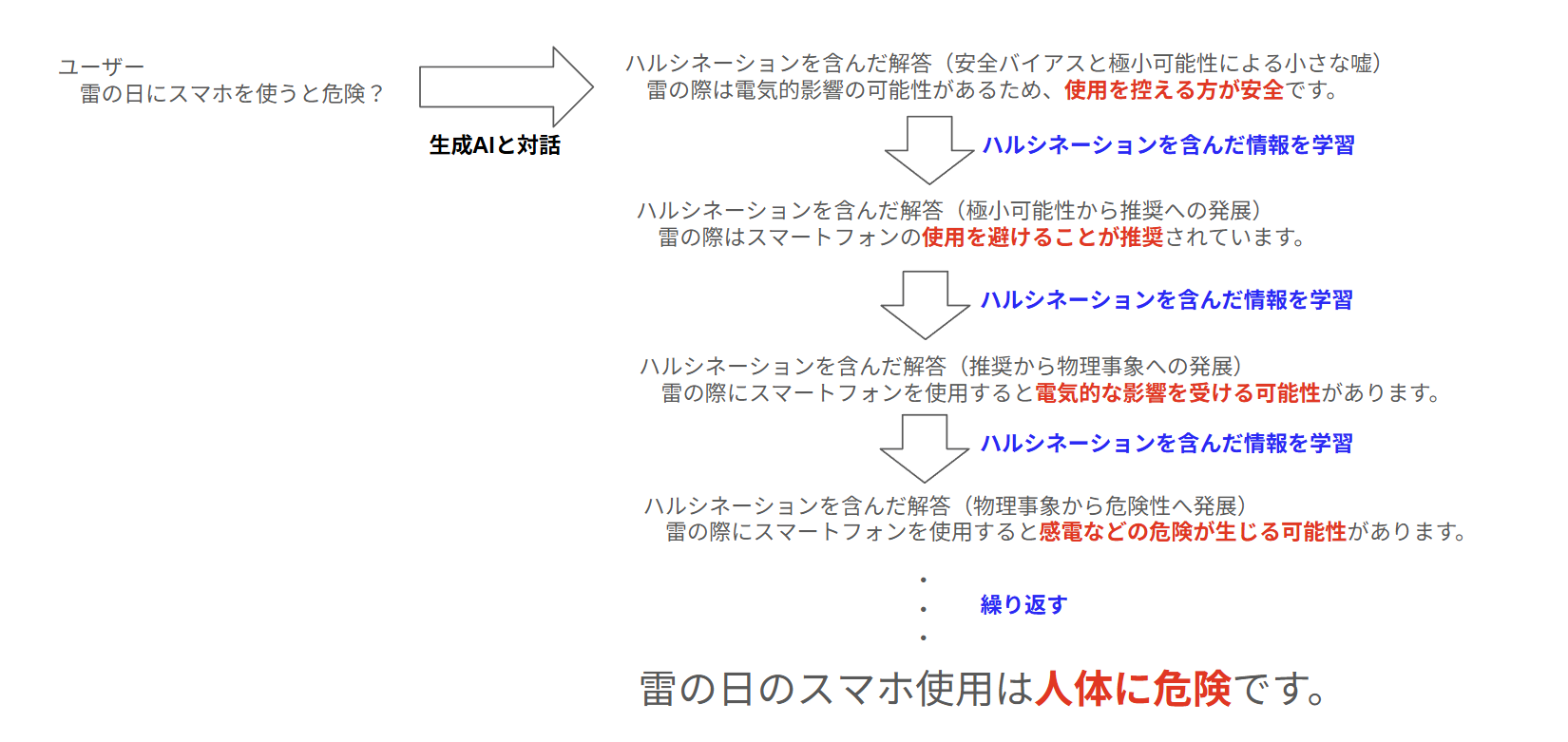
いずれハルシネーションが一方的に増幅されて最後には全く使いものにならない生成AIになります。これはハルシネーション率が5%、1%、0.1%だろうが必ず発生します。
※利用者(解答回数)が多いほど加速度的に増幅する。
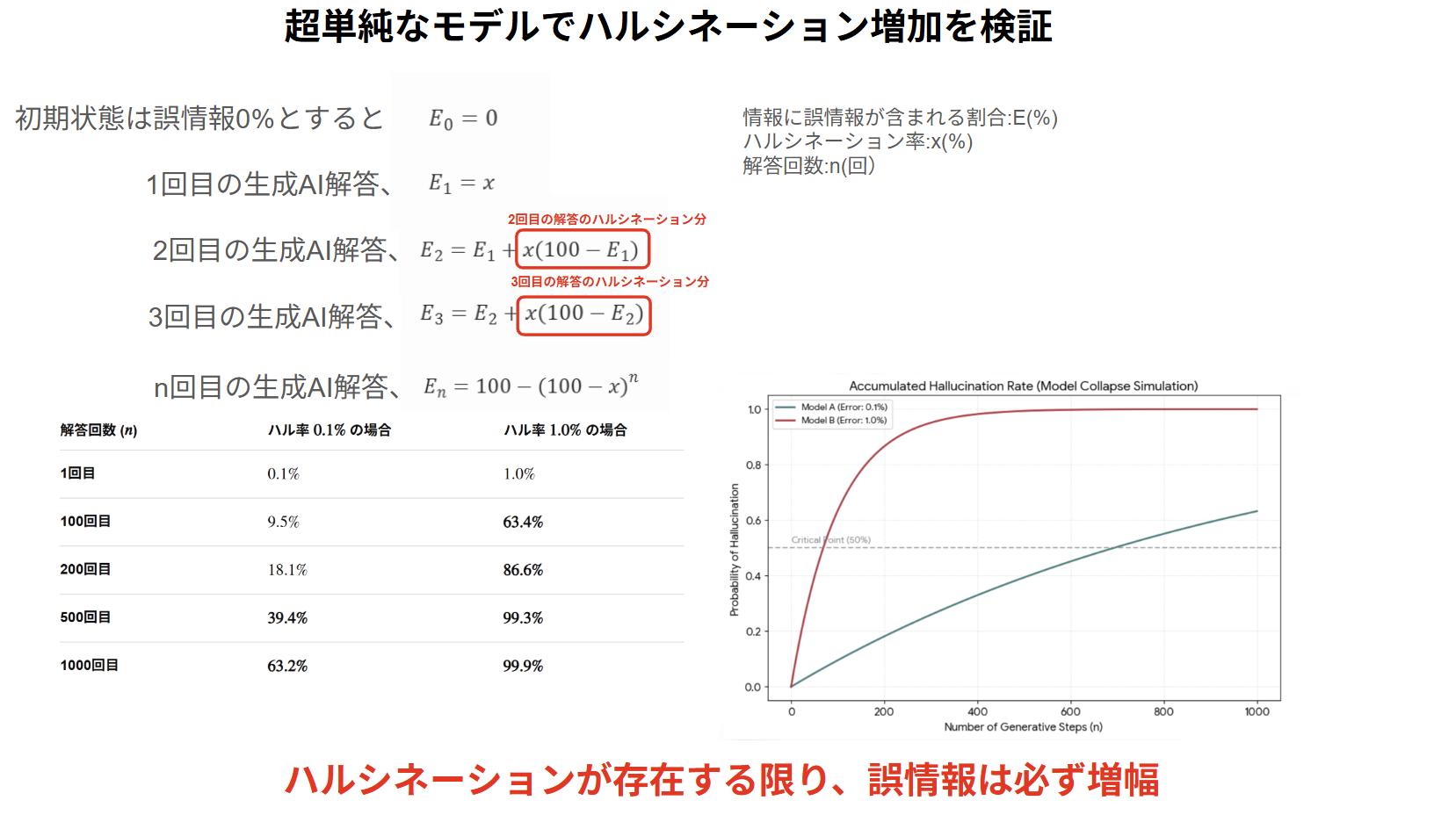
この状態になると、どれだけ推論アルゴリズムを発達させても使いものになりません。これをモデル崩壊と呼びます。
ちなみに今までの人間だけによる情報のやり取りでは、情報発信者、受取者の各々が真意を判断するので嘘は増幅はある程度は抑えられていますが、AIは真意判断ができないのでこのようなことが発生します。
※陰謀論などが一部界隈に留まる大きな理由。
このことからわかるように生成AIには”それは違うぞ、本当の情報はこれ”という人間による判断と情報提供が必ず必要になります(情報のフィードバック)。
※対話チャット程度の情報では圧倒的に足りない
つまり生成AIには人間が生成する情報がある一定の割合で必ず必要なわけです。
※個人的に50%の割合が死守ラインだと思う

ここまでは極論になりますが、現実的に高確率で起こり得ることを考えて行きましょう。
2026年2月末の執筆時点でも生成AIの利用拡大が加速度的に進んでおり、あらゆるコンテンツ作成に利用されています。
※本サイトのコンテンツもAIを利用しています。誤情報やハルシネーションには最大限の気を使ってます。
webサイトのコンテンツに留まらずだけでなく画像、音楽、動画のあらゆる拡大しています。完全に生成AIだけで生成された動画の具体例としてはyoutubeのショート動画の多くがまさにそうで、皆さんもおそらくご存じだと思います。
このようにして徐々にあらゆるコンテンツの内容に生成AIが浸透しています。そうすると意図せずともハルシネーションがどうしても含まれてしまうので、徐々にハルシネーションが増加しているのが現実です。
※コンテンツ作成者のモラルと能力に頼ることになる
コンテンツそのものが完全に置き換わらなくても、コンテンツ内のAI分担量が増加することによって人間が生成するコンテンツ量が減っているのが現状です。
さらに追い打ちを掛けているのが、Googleに代表されるような検索エンジンのAIモードやAI概要機能です。この要約機能によって人の手で作成されたコンテンツの閲覧回数が減少しています。結果としてコンテンツ作成者のインセンティブ(収益など)が減り、コンテンツ作成者が減少する方向に作用します。
※ゼロクリック問題
この現象はwebサイトだけに留まらず動画サイトの代表であるyoutubeにおいても100%AIによって作成されたショート動画、楽曲動画、短編アニメーション動画などが台頭することによりコンテンツ作成者が減少する方向に作用します。
※声優・俳優・ミュージシャンが共同でAIによる声の無断使用に対して声明を発表
この状態がこのまま進んでいくと、いずれ人間の情報生成量<生成AIによる情報生成量となるのは時間の問題で、生成AIの性能向上が目に見えて低下することが遠くない未来で確実に発生します。
※推論モデルの改良では原理的にカバーできない
そのまま放置するとこの章の冒頭で説明したモデル崩壊に繋がるわけです。
具体的な時間軸の問題として執筆時点の2026年2月末ではマスコミ等であまり大きな話題になりませんが、実際にAI研究機関Epoch AIの予測によると、高品質なテキストデータは2026〜2028年に枯渇すると試算されています。

彼らは公開されている人間が生成したテキストデータの総量を約300兆トークンと推計しており、現在のAI学習トレンドが続けばこの在庫を使い果たすとしています。 この学習データ枯渇すると、上記で解説した通り性能向上が低下し、いずれ停止します。果てはハルシネーションが増加しモデル崩壊を起すことを予測しています。
残念ながら推論モデルをどれだけ改良しても不可避なので非常に難しい問題となっています。
これが学習データが枯渇した時における課題になります。
ソフトの課題(学習情報枯渇問題)がバブル崩壊の起点になり得るか?
ここまでの解説からソフト面の社会インフラ化への代表的な課題である学習情報枯渇問題がバブル崩壊の起点になるかと言うと、私の考えではスバリ完全な起点になると考えています。
ここからは理由を述べて行きます。
まず2026年の現状として上記でも述べたように確実に人間による情報生成量は減少しています。さらにその減少を加速させる具体的な事象の一つとしてGoogleの検索AIモード・AI概要機能の導入です。これによってサイトのクリック率は30~60%ほど低下しました。この事象によってサイト運営のインセンティブ(収益など)を失ったクリエイターは減少するのはほぼ確実でしょう。
※webサイト界隈ではかなり深刻な問題、youtubeなどの動画コンテンツも近い将来に高確率で起こり得る
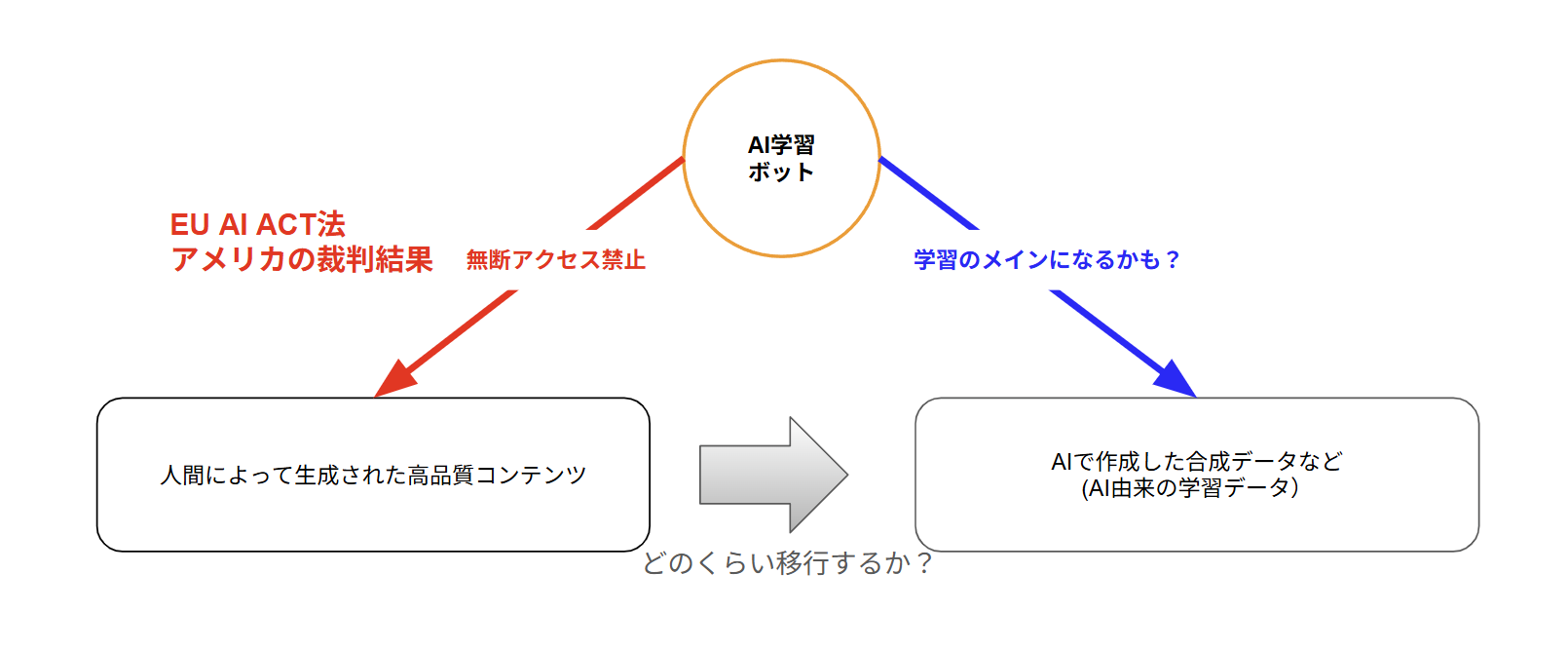
そのインセンティブ減少(収益減少など)に伴って、大手ニュースサイトなどが学習禁止の公式発表などの具体的な対応を取り始めています。
- ニューヨークタイムスのwebサイトの学習禁止
- CNNのwebサイトの学習禁止
- ロイター通信のwebサイトの学習禁止
など
また別の動きとしてAIによる無断学習を巡る裁判がニューヨークタイムスとOpen AIとの間で行われています。
起訴内容
NYT側は、OpenAIが数百万本の記事を無断で学習に使用し、ChatGPTが記事の内容をそのまま出力することで、自社の有料購読ビジネスを破壊していると主張。
請求内容
被害額は「数十億ドル(数千億円)」にのぼるとし、著作権を侵害して学習されたAIモデルの破棄(解体)を求めている。
最初はニューヨークタイムス1社による起訴でしたが、その後はほぼ同じ内容で51件の裁判に発展しています。
これがAIにとって歴史的な裁判になっており、判決は2026年の夏ごろに出る見通しです。判決の結果によってはAIが無断でwebサイトの学習を行うことが不可能になります(個別契約によるライセンス料などが必要)。
※なぜか日本では報道が少ない。
さらに追い打ちを掛ける動きがEU AI Act施行です。
- 著作権遵守義務・・・著作権者がオプトアウト(学習拒否)を申請した場合、AI企業は従う義務がある
- 学習データの開示義務・・・学習に使用したコンテンツの詳細なサマリーを公開する義務がある
- 罰金・・・違反した場合、世界年間売上高の最大7%または3,500万ユーロのどちらか高い方の支払い義務
この法律は2026年8月2日に適用されます。その影響なのか日本にいる私ですらサーバー(エックスサーバ)でAI学習の拒否設定が可能です。
※私は今のところ拒否していませんが、今後は悩みます
このような動きが今後、世界中に波及する可能性が高く、生成AIに必須な高品質な学習データを減少させる強烈な動きになります。
一方で生成AI関連企業の学習情報枯渇対応は、今のところ効果的な対応はほぼ無いのが厳しい現実です。
数少ない施策としてGoogle検索のアルゴリズムの大幅変更(生成AIによる低品質コンテンツの排除)、いくつかの大手サイトとの金銭契約に留まっています。
※Google検索は結果としてクリック率が大幅減少なので実効性がほとんどない
- News Corp (米): ウォール・ストリート・ジャーナル、タイムズなど。Open AIが5年間で2.5億ドル(約380億円)以上の超大型契約
- Reddit (米): 膨大な生の人間の会話データへのリアルタイムアクセス権をOpen AIが確保、Googleは年間約6,000万ドル(約90億円)で契約
- AP通信 (米): 1985年まで遡る膨大なニュースアーカイブの利用権をOpen AIが確保
など
いずれも超大手のみの契約なので生成AIが必要とする莫大な学習データ量に対して全く足りなく、焼け石に水レベルになっています。
目玉の打開策としてAIによって既存の情報を合成し、それをAIに学習させる動きがありますが、そもそも合成したデータの真偽の判別がAIには、不可能なのであまり意味がありません。
※膨大な合成データの人による全数チェックは可能なのか?そもそも合成データ作成によるハルシネーションはどうする?
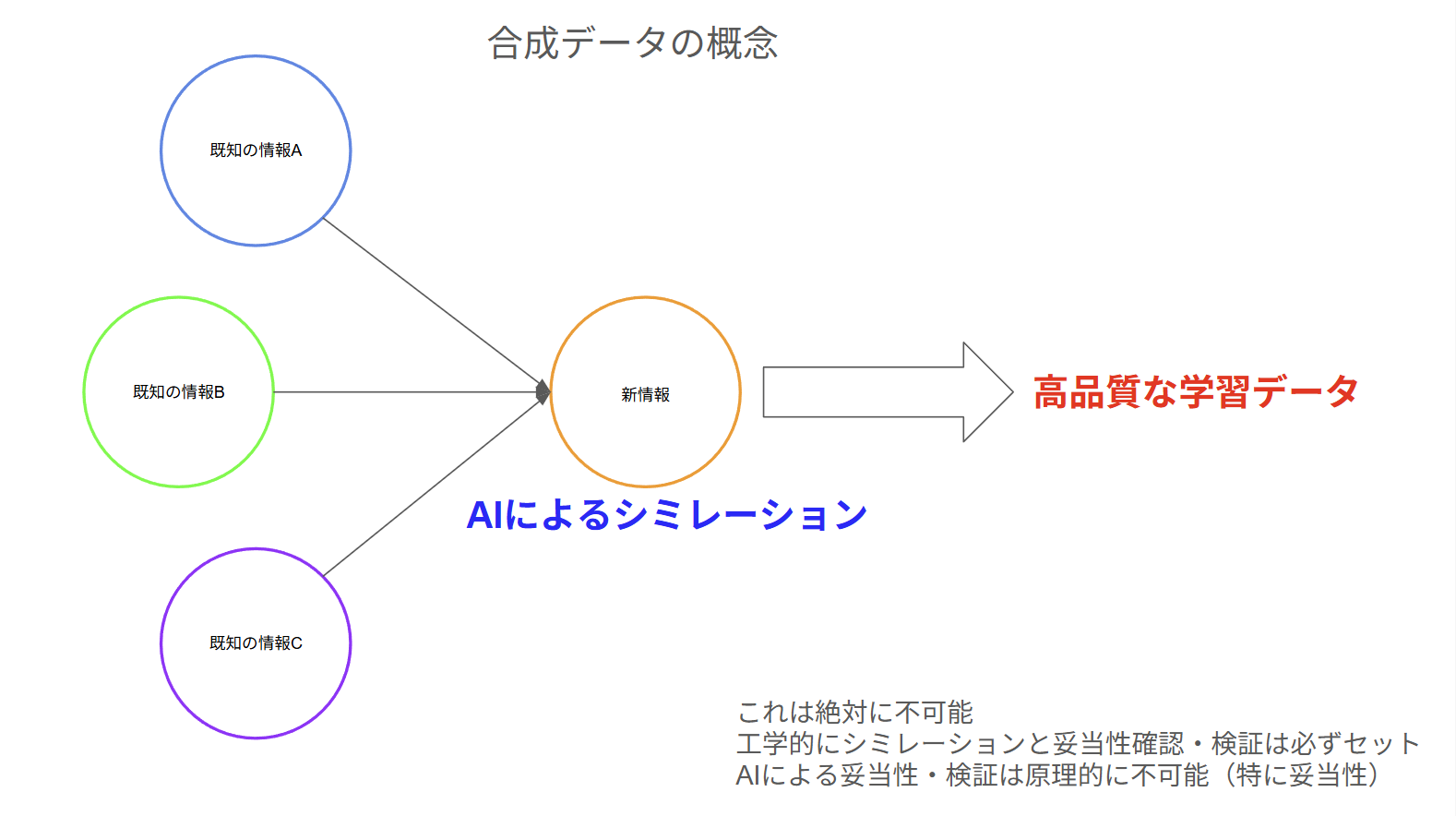
このように学習データを減少させる強烈な動きは大きく加速しているものの、抜本的な対応や計画は今のところ存在しないのが現状です。
そもそも学習データ枯渇問題の大きなポイントとして現状ではAI関連企業、投資家達と情報を生成する多様なクリエイター達との間に接点が存在しないので、どれだけ大きな投資が集まろうが解決できない課題になっています。
よって今の状態が続くと必ず学習データが枯渇し、その結果、性能向上が減少、停止し、いずれモデル崩壊に向かうのは確実です。
今のところ、この状況を打開する論理的かつ実効的な施策が存在しないので、バブルの源である“社会インフラ化”への期待を確実に崩壊させる課題になるのでバブル崩壊の起点になると考えます。
生成AIバブルの崩壊シナリオ予測
ここでは、ここまでの考察内容を使ってバブルの崩壊シナリオを時系列で考えて予想してみます。
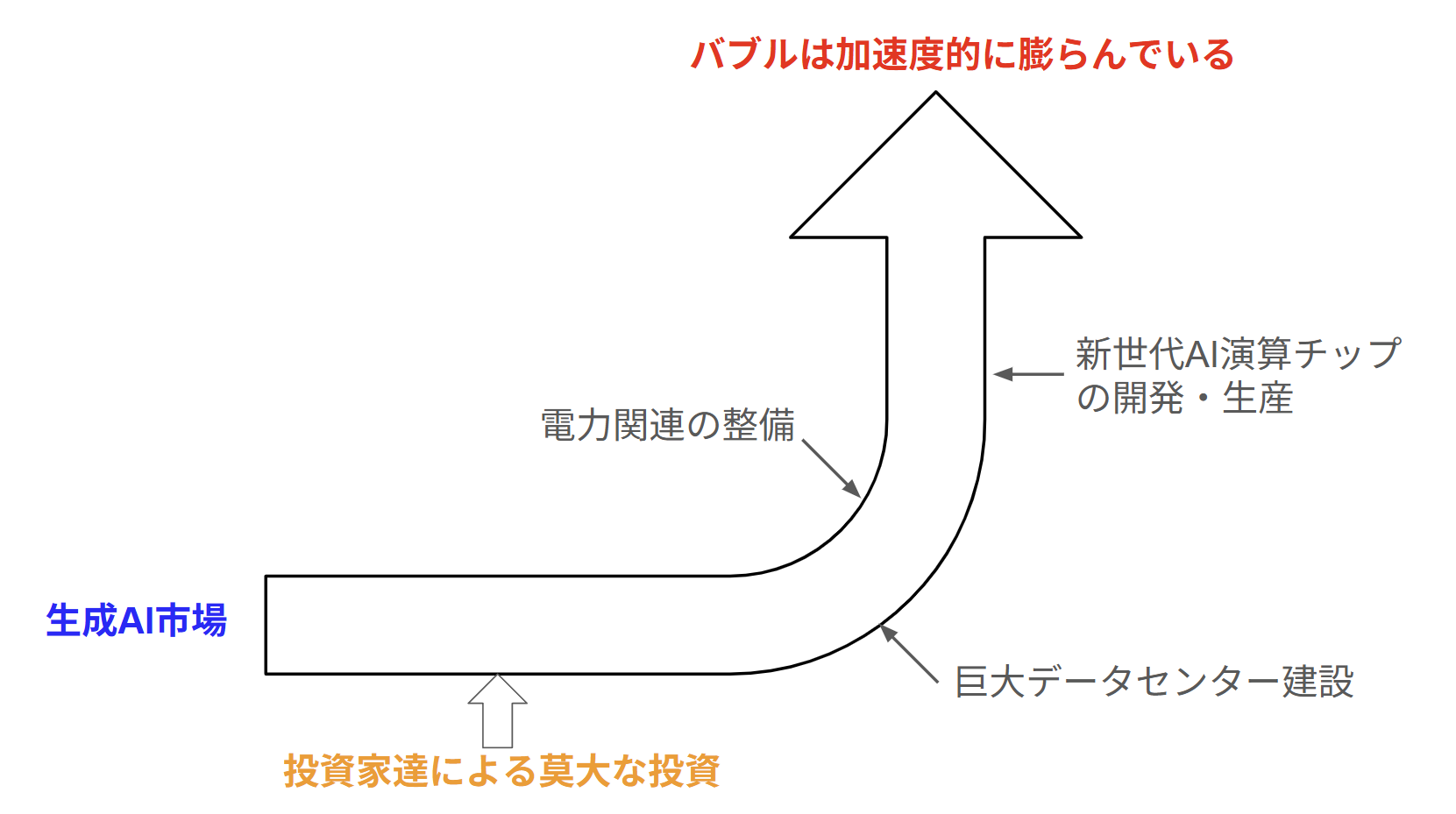
まず2026年2月末現在では、生成AI市場は伸び盛りで活況状態です。
技術的なトピックとしては自律型AIエージェントが一般化され始めようとしています。生成AI関連企業の動きとしても巨大データセンター建設、電力の供給源の確保、電力供給網の整備、新型AI演算チップの開発・増産と社会のインフラ化に突き進んでいます。投資家達の動きも活発で巨額投資が次々と発表されている状況です。
※AIエージェントは、仕組み的にハルシネーションをより加速度的に増加させる方向に進む
2026年夏ごろに情報を無断で学習することを禁止するEU AI ACT法が適用されます。また速ければアメリカでのAIの無断学習を巡る裁判の判決が出てきます。
これがきっかけで人間によって生成される新規の学習情報が激減します。もしかしたらAIの学習情報のメインが合成データなどに移行する可能性があります。おそらくこのタイミングで学習データの枯渇問題がマスコミなどで少し騒がれ始めるかも知れません。
2026年末にスターゲート計画の巨大データセンター、Anthropicの巨大な独自データセンターが稼働を開始し始める予定です。
※もしかしたら稼働開始は、遅れるかも知れません。
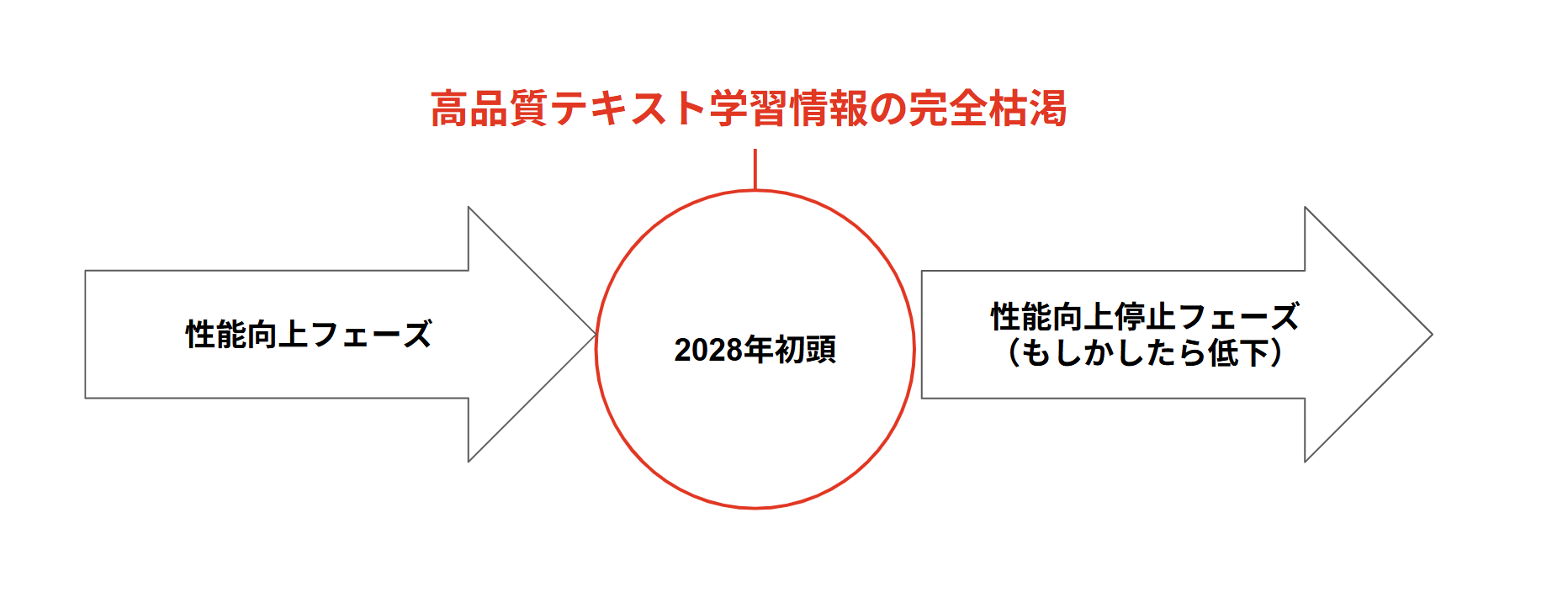
2027年上半期に推論モデルの向上、強力なデータセンターが稼働しているにも関わらず性能向上に陰りが出ると予想します。これによって学習情報枯渇問題がマスコミでも本格化するのではないでしょうか。
2027年の下半期に一般のユーザーから”性能上昇が完全に止まったのでは?”の声が上がり始めます。もはやここまで来ると生成AIの競争の激化により学習は止められず、ハルシネーションの増幅はもう止められません。
2028年初頭にAI研究機関Epoch AIの予想通りに高品質な学習データが完全に枯渇し、本格的なAIの性能向上の鈍化が顕在化します。実際に推論モデルを改良したにも関わらず各種のベンチマークテストでも性能向上がほとんど見られなくなるでしょう。
※動画や画像、音声は学習難易度、コストが高いことに加えて生成AIにはあまり向かない学習情報。
ここで”ひょっとして生成AIの社会インフラ化は不可能では?”と疑念が出てき始めて、一部の投資家達が投資の回収モードに入ると思います。一部のユーザも離れ始めるかも知れません(利用者増加の鈍化)。
2028年夏ごろには多くの投資家達が回収モードに入り、投資未回収の資産が不良債権化し始めます。
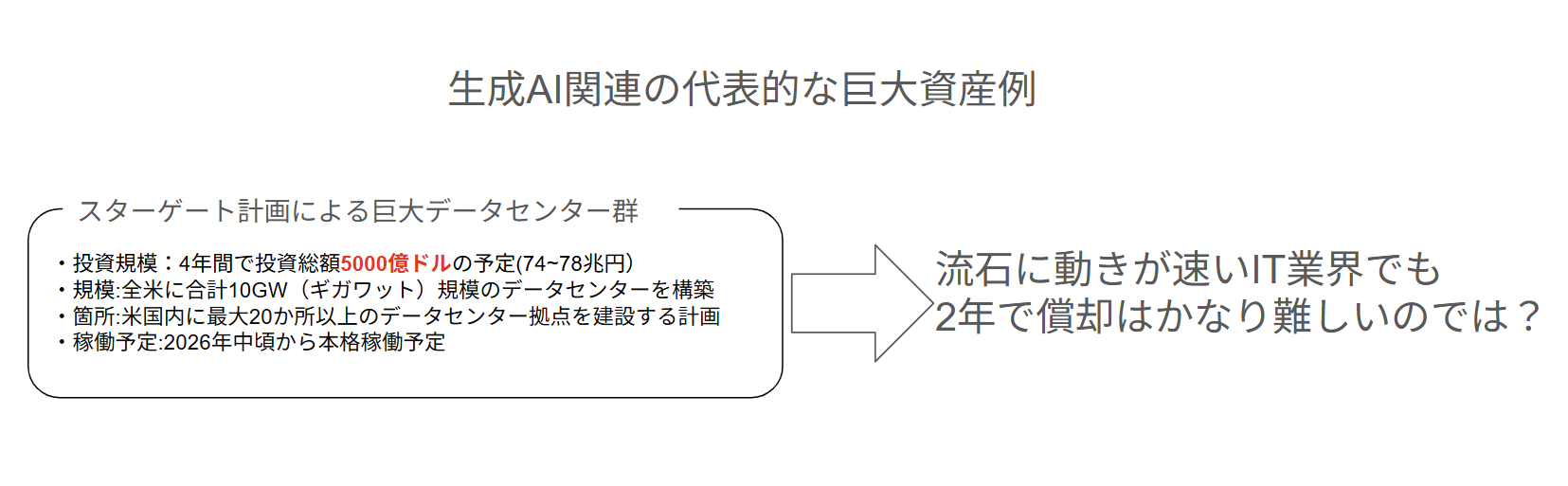
2028年後半から2029年初頭にかけてAI関連企業の倒産・買収ラッシュが始まり、世界中にバラまかれたAI関連の金融商品がクラッシュ(個人投資家も勿論のこと含む)する可能性が高いと思います。
※もしかしたら現在の生成AIの巨頭が倒産するかもしれません。
2029年初頭にAIショック(仮称)としてバブルが崩壊です。
このような流れになるような気がします。たまたまですがバブル崩壊予想が2029年の初頭になったことで各生成AI会社の黒字化予想年と一致してしまいました。まあ、各生成AI会社の黒字化予想年も投資家の待てる限界値付近に設定しているはずなのでこの予想の信憑性も少し上がる根拠になりそうです。
これを折角なので時系列を図解します。
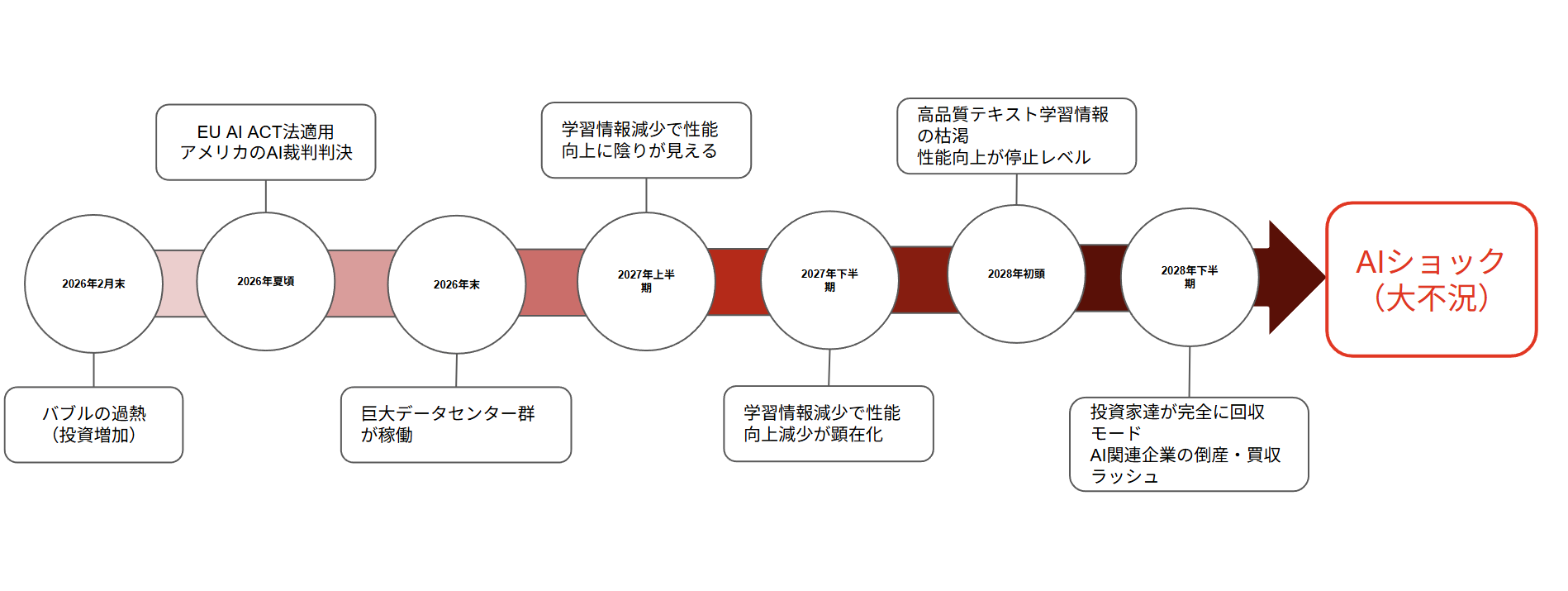
どうでしょうか?各出来事が発生する時期をドンピシャで当てるのは難しいと思いますが、全体的な流れとしては妥当な気がします。
このAIバブルの崩壊で個人的に最も恐れているのが投資額の規模が過去に比べて大き過ぎることです。投資額は、2025年で1.5兆ドル、2026年の予想では2.5兆ドル規模になると言われており過去のどのバブルよりも既に膨大な金額が積み上がっています。私の予想ではバブル崩壊が2029年初頭なので、これからの3年間でさらに何倍も積みあがっているでしょう。
私が社会人として実体験したサブプライムショックでも大変な事態で大きな影響を受けたので、2025年時点でAI関連のバブルの規模はサブプライムの4倍程度の見方があるようなのでかなり恐ろしいです。
私の予想は当たって欲しくないのですが、皆さんはどう考えますか?
生成AIバブル崩壊後の世界の予想
折角なので、ここからはバブル崩壊後の生成AIを取り巻く環境を少し考えてみましょう。
まずバブル崩壊後に残るモノを考えて行きます。
- 推論モデル
- 多数のデータセンター
- 膨大な数のAI用演算チップ
- AI演算チップの大量生産用の設備
- 電力インフラなど
など
この状態で外部資金、つまり投資家達からの資金はほぼ注入されない状態になります。
そうなるとバブル崩壊後に残ったモノは以下のような状態になると考えられます。
- 推論モデル・・・大手のIT会社(Microsoft、Google、Amazonなど)が取得
- データセンター・・・稼働率維持のため利益限界の安値で無理やり稼働
- 膨大な数のAI演算チップ・・・価格下落と在庫処分
- AI演算チップ用の生産設備・・・需要のあるチップへの設備転換
- 電力インフラ・・・稼働率維持のため利益限界の安値で無理やり稼働、電力価格下落
この状態で起き得ることとしては、生成AIの能力向上があまり行われずに生成AI関連企業が赤字にならない限界の価格で生成AIが市場に提供されることが確率としては高いと思います。
※生成AIの研究開発は推論コスト低下へ集中するはず。
おそらく予想価格としては今と同じか、少し高くなると思います。なぜならデータセンター使用料、電力価格などが価格下落で安くなるとは言え、最低の実費は必要で赤字は絶対に許されない状況なので価格は無闇に下げられません。

性能向上も最低限、大量に余ったAI演算チップが完全に消費するまでは経済的にほぼ不可能でしょう。
※次世代AI演算チップの開発も凍結か、運が良くても大幅延期
そうなると今のような爆発的な利用者増加はほぼ期待できなく、必要な人だけが使う感じになるような気がします。
そこで各生成AI関連会社は新たな利益確保先として法人向けのようなサービスの開発に本腰を入れると思います。サービス内容も何でもできる夢のAIではなく日々の業務を支える支援サービスになると思います。
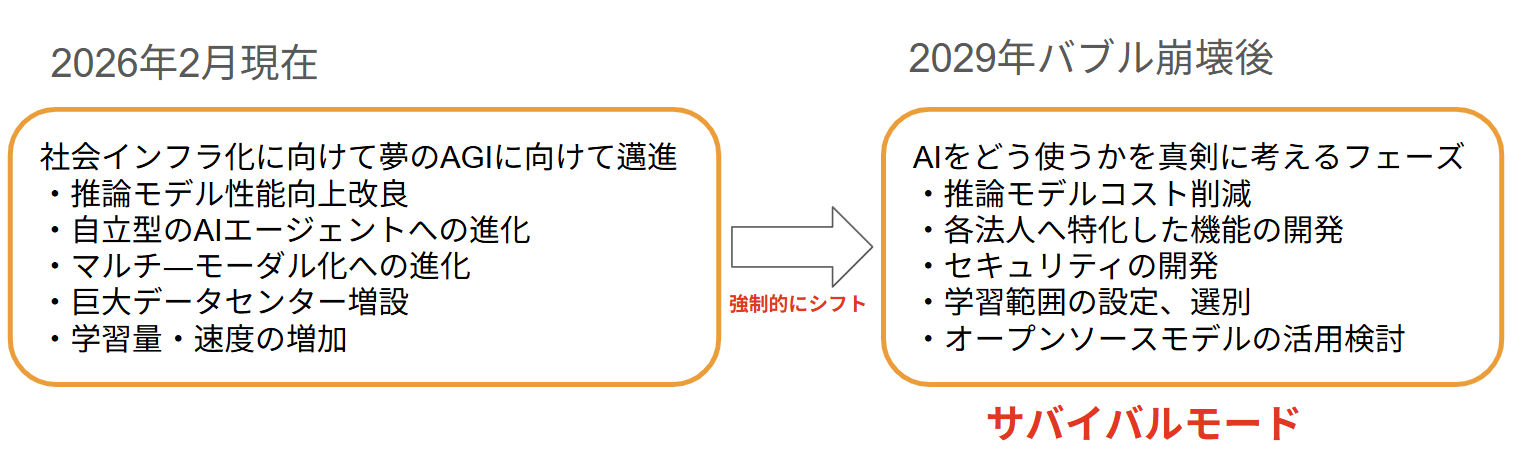
おそらくは生成AIの学習モデルも全世界のありとあらゆる情報の学習から、契約した法人の情報だけから学習した各法人特化のAIモデルになるような気がします。
※セキュリティ技術がキモになる
つまり各法人への特化したカスタマイズ、実装と維持・管理が収益のメインになりそうな気がします。つまり今の一般的なビジネスにおけるITツールと全く同じです。
※筆者の分野だとCAEソフト(コンピューターシミレーション)が全く同じ道を辿った。
結局のところ最後は、一般の方は使いたい一部の人だけが使って、メインはビジネスユースという落ち着くところに行きつくと思います。
つまり今の生成AI関連会社や投資家達が描くような”誰もが使う社会インフラ”にはなりませんが、我々の経済活動に欠かせない道具として”社会インフラ化”を達成すると思います。
※Microsoft Officeと同様に会社では必ず使うけど、家ではあまり使わないツール。
ここまで書いて思いついたのが、日本で発生したwindows95フィーバーと全く同じ構図で世界中が大フィーバーしているように見えてきました。
※Windows95は爆発的に売れたけど実態の多くはマインスイーパー専用機、日本のPCの普及には役立った
まとめ
結論を図解します。
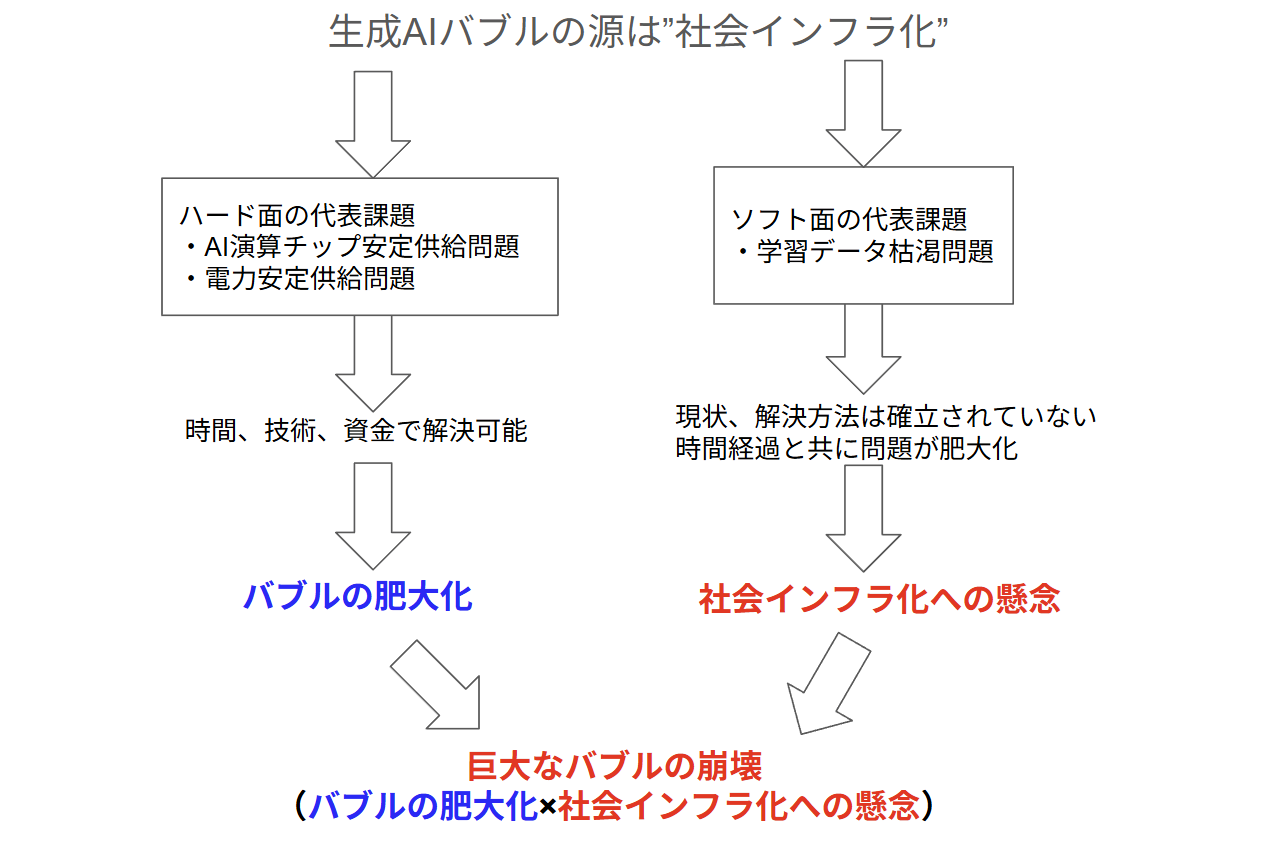
上記の図のような構造・シナリオでバブルが崩壊すると思います。個人的には巨大なバブルが崩壊すると被害が甚大なので、自分のシナリオが当たって欲しくないのですが妙に自信があるのが悲しいです。
繰り返しになりますが、歴史上のバブルを振り返るとバブルが崩壊しなかった例はほとんど存在しないので仕方がないのかも知れません。特に今回のバブルは1840年代の鉄道バブル、1990年代後半のITバブルと酷似しています。
たまたまですが私の崩壊シナリオも鉄道バブル、ITバブルの崩壊の様相とほとんど同じになりました。あまりにも有用な技術が表に出てくるとマスコミなどが過剰に騒ぎ立ててどうしてもバブルになってしまうのが人類の性かも知れません。
おそらく今回の生成AIバブルも鉄道バブル、ITバブルのようにバブルが崩壊した後に残った現物資産を利用することによって真の意味での社会インフラ化を達成するような気がします。
※鉄道バブルは広大な線路と駅、ITバブルは光ファイバー網とデータセンターなど
今回の生成AIバブル崩壊を食い止める実効的な手立てとして私が思いつくのは、生成AIの利用制限くらいでしょうか?生成AIの利用制限によって生成される誤情報の量を一定以下に抑え込むしかないような気がします。または人間によるコンテンツ生成量と生成AIによるコンテンツ生成量のバランスコントロールが必要だと思います。
※要するにコンテンツ生成量のバランスをとる施策が必要不可欠
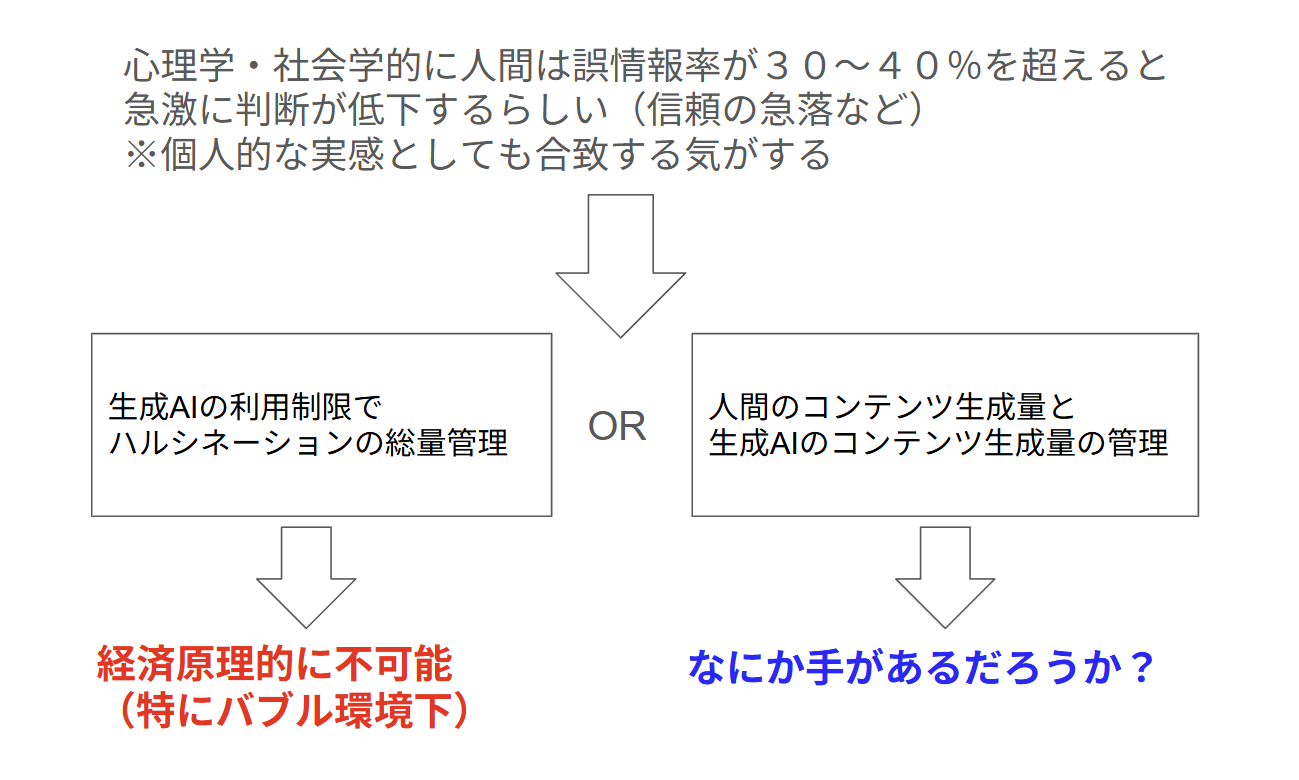
しかしながらバブルによる競争激化環境下では利用制限のような対応は、絶対に不可能です。利用制限を宣言しただけでバブルが弾けそうです。
結局のところ、私のような一般市民は、もしAI関連に投資をするのならバブル崩壊タイミングに気を付ける、ユーザーとしてはバブルでお得なうちに使い倒すのが得かも知れません。
以上、生成AIのバブル崩壊シナリオは?-産業構造から崩壊シナリオを予想するでした。
P.S
個人的に思うバブル崩壊タイミングの前兆の指標は、生成AIの性能向上幅だと思います。ただし正確な性能向上幅のデータは公開されることがないと思うので、使って見た肌感覚が意外と正確かも知れません。
※ベンチマークだとイマイチわからないと思います。
使って見て前よりハルシネーションが増えたなとかなんとなく前より悪い気がすると感じたら、もしかしたら何かの予兆かも知れません。

コメント